Twitter
fl_in_academia
micolich
Search
Home
About
Disclaimer
Archive
Reading List
Latest
Advice for Undergraduates
,
Higher Education Policy
,
University Leadership
UNSW’s ‘Clayton’s’ Student Misconduct Appeals Process
Clayton’s… the appeal process you have when you’re not interested in having appeals.
Adam Micolich
January 22, 2024
Shorts
Christmas Presents & View to 2024
Adam Micolich
December 23, 2023
EDI Issues
,
Higher Education Policy
,
University Leadership
,
Workloads in Academia
Workloads #3 — The Role for Academic Leadership
Adam Micolich
December 6, 2023
Academic Life
,
EDI Issues
,
Mental Health
,
Productivity Hacks
,
Workaholism
,
Workloads in Academia
Workloads #2 — How hard does Adam really work?
Adam Micolich
November 26, 2023
Academic Life
,
Higher Education Policy
,
University Leadership
,
Workloads in Academia
Workloads #1 — Reforming our Departmental Workload Scheme
Adam Micolich
August 15, 2023
Most Viewed Posts
12 guidelines for surviving science…
Adam Micolich
January 2, 2015
We’ve gotta stop worshipping workaholics…
Adam Micolich
July 14, 2015
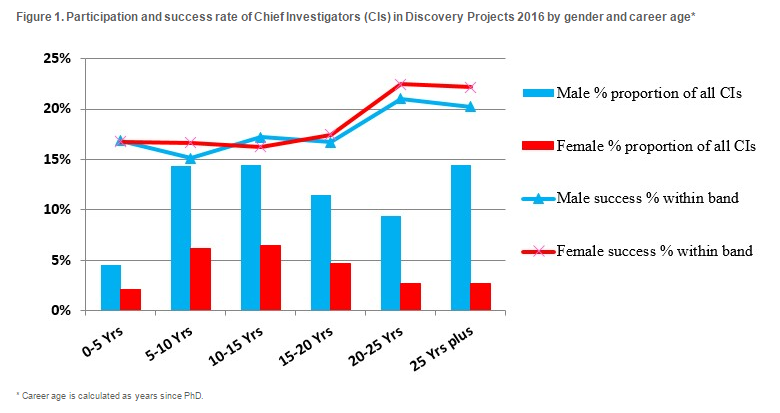
Fixing ARC Discovery Projects
Adam Micolich
October 30, 2015
Physchosis: How academia destroys your mental health.
Adam Micolich
April 6, 2016
How to organise a conference that makes science a better place…
Adam Micolich
October 16, 2017
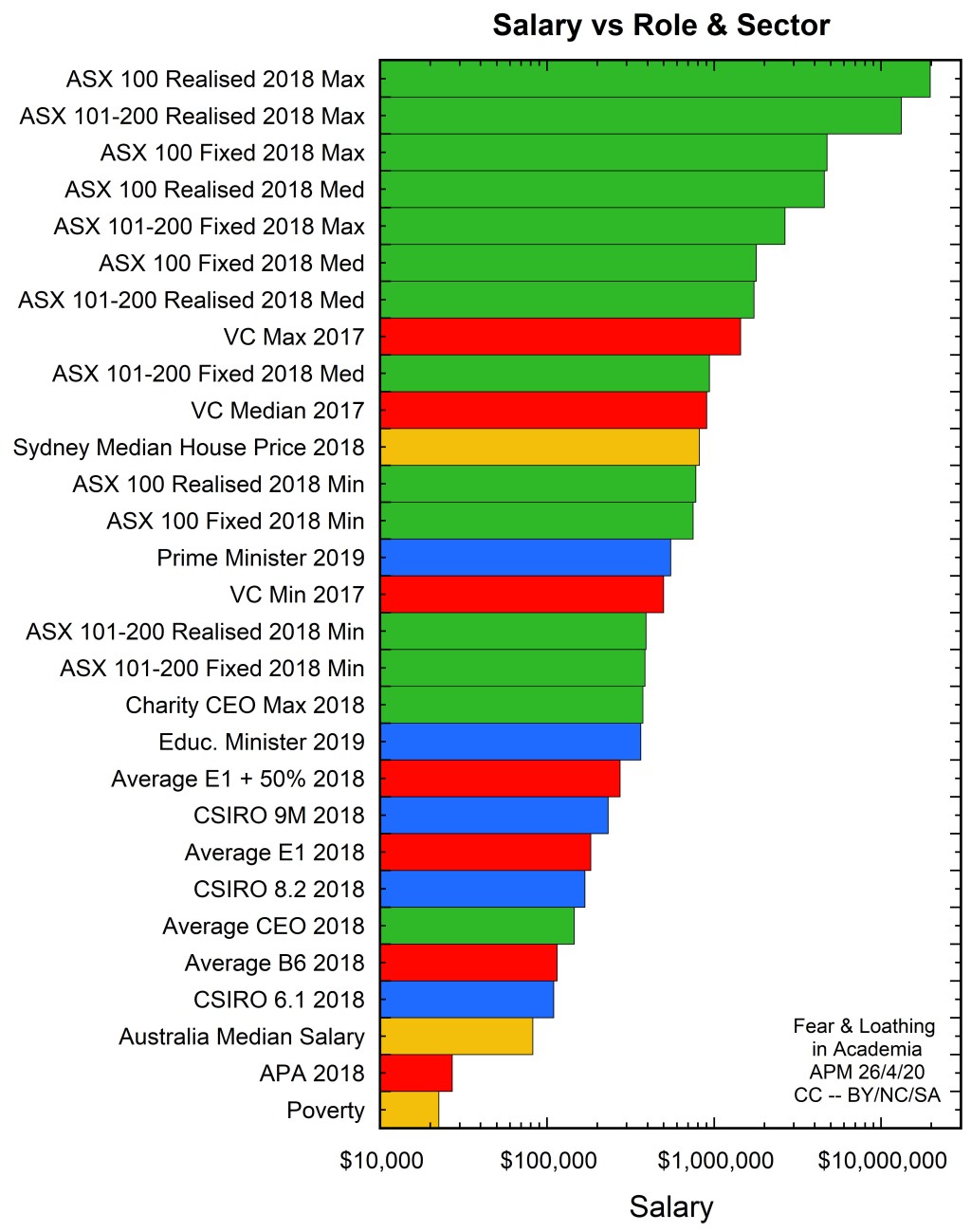
Game of Gowns — The spoils of #ponzidemia
Adam Micolich
April 27, 2020
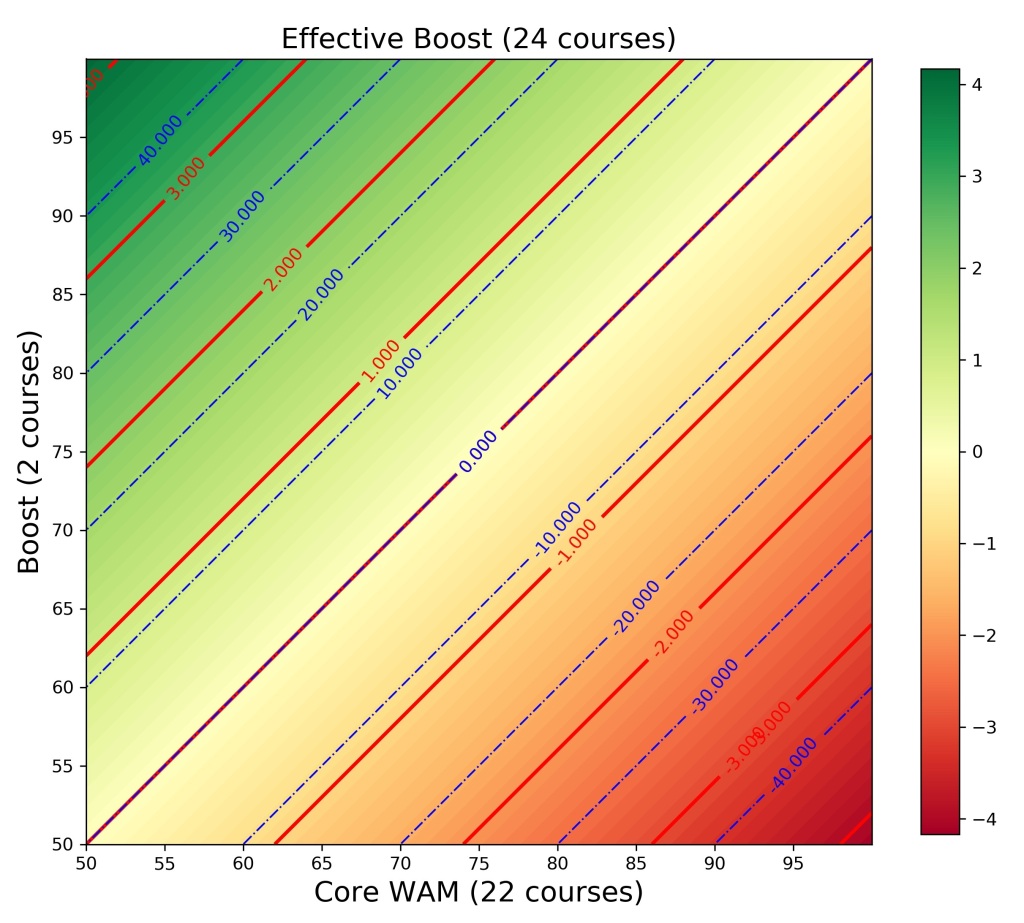
WAM Booster Courses: Magic or Myth?
Adam Micolich
April 25, 2021
ChatGPT gets an A (for Anything but Average)…
Adam Micolich
May 12, 2023
Privacy & Cookies: This site uses cookies. By continuing to use this website, you agree to their use.
To find out more, including how to control cookies, see here:
Cookie Policy
Subscribe
Subscribed
Fear and Loathing in Academia
Join 109 other subscribers
Sign me up
Already have a WordPress.com account?
Log in now.
Fear and Loathing in Academia
Edit Site
Subscribe
Subscribed
Sign up
Log in
Report this content
View site in Reader
Manage subscriptions
Collapse this bar